


本文与其他介绍optimizer有所不同的是:
- 本文完整地阐述了批量学习、在线学习两条路线的optimizer进化史
- 本文只从感知上进行理解,不涉及数学推导,着重于记忆与理解,而非严肃的论文体
- 本文为了从理解入手, 改变了原论文中的公式形式
文本结构
源头:SGD
批量学习优化器
momentum
NAG
AdaGrad
RMSProp
AdaDelta
Adam
可视化对比
进展
在线学习优化器
TG
FOBOS
RDA
FTRL
进展
每次使用一个样本计算损失函数, 从而得到梯度, 逐步的迭代参数
使用一个样本容易陷入局部最优点, 且迭代速度慢,容易产生震荡,批量学习正是解决这个问题的方法.
当然在线学习有另一条路子解决,且在线学习是为了参数稀疏化而生的,更适用于搜广推领域.
momentum在SGD的基础上加上了惯性, 即如与上一步方向一致,加快速度,与上一步方向不一致减慢.但当局部最优点很深时,动量也无法拯救.
NAG在SGD的基础上加入了看一步走一步的机制, 即将提前计算一步梯度, 防止小球盲目跟随上一步动量,冲出最优点.
极小的数防止分母为0前面的优化器的学习率都是固定的, 而AdaGrad可随着模型的收敛自适应学习率. 即更新频率高的维度学习率逐渐减缓, 更新频率低的维度维持高学习率.
AdaGrad 暴力的随着梯度累计越高, 学习率越低. RMS对此做了改进,只取一个窗口下的梯度平均值.
AdaGrad 和 RMSProp 都得初始化学习率,可不可以连初始化都不用呢?AdaDelta给了答案
可以理解为动量+学习率自适应


- SWATS 2017
- AmsGrad 2018
- AdaBound 2019
- RAdam 2019
- AdamW 2019
- RAdam 2020
在线学习的优化器用于流式数据的训练,对于数据量相当庞大,且数据相对稀疏的场景尤为合适。
简单截断法
如何训练出稀疏性的参数呢?简单的想法就是设置一个阈值,小于这个阈值直接置零。
如此暴力的做法会导致一些训练不足的参数置零,于是就有了优化版本:
梯度截断法
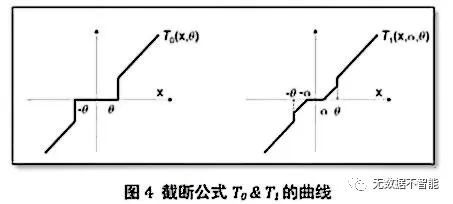
别被公式吓坏了,下图可更加直观地看出区别,梯度阶段法由两个参数控制稀疏度。直观的理解:参数接近0时,推波助澜至更接近0;更进一步接近0时,直接置零。这比简单截断法要顺滑一些。
FOBOS将此问题拆解成了两部分,在梯度下降之后,加入了一个优化问题。即控制梯度下降得到的结果不太远的第二范数,以及增加稀疏性的第一范数。
FOBOS只是拿了本步的梯度下降结果,在在线学习这种流式学习中,一次只学习一条数据,很容易造成参数的波动,参考的更远,可以减少这种异常点波动。
这不,RDA来了,RDA优化的第一项是梯度对参数的积分平均值,第二项是第一范数(增加稀疏性),第三项第二范数约束参数不离零太远.
FTRL是RDA和FOBOS优点的合集,即又考虑与之前的参数距离,又考虑本步梯度下降的结果.
- FTML 2017
- SGDOL 2019
- STORM 2019
- EXP3 2019
- UCB 2019
本文中的公式纯手敲,且为了理解的方便,没有写成原论文的公式形式, 如有错误之处可联系进行改正
本篇【理解优化器】为【理解XXX】系列文章
更多【理解XXX】系列文章,请关注【无数据不智能】公众号


