

上一节笔记:
学弱猹:数值优化(7)——限制空间的优化算法:LBFGS,LSR1————————————————————————————————————
大家好!这一节我们会开辟一个全新的领域,我们会开始介绍带约束优化的相关内容。带约束优化在某些细节上会与之前的内容有所不同,但是主要的思路啥的都会和我们之前的传统方法一致,所以倒也不必担心。
那么我们开始吧。
- 带约束优化问题的基本框架与支撑性质
- 优化边界举例
- 梯度投影法
- 标准化的梯度投影法
- D. P. Bertsekas. Nonlinear Programming
- C. T. Kelley. Iterative Method for Optimization
- 课堂笔记,教授主页:
一般来说我们会研究的问题长这个样子
其中是实值函数,并且在很多情况下,这里的
都是凸集。在带了约束的情况下,我们的所有的优化步骤都必须局限在约束内。所以自然需要引入很多额外的定义,也就是说在介绍具体的方法之前,我们会用大量的定义和定理为大家构建一个带约束优化问题的框架,这样的话在遇到一些带约束优化特有的情形的时候,就不会感到奇怪。
首先是下面这个定义
Definition 1: Projection
设为一个在希尔伯特空间内的凸集,那么对任意的
,我们定义它到
的投影为
,这里的范数定义为内积生成的范数,也就是
。
说它是投影也无可厚非,只不过这个投影和单纯的“投影到地面上”啥的相比,做了一个拓展。所以关于这个投影,是否还具有一般的性质呢?这就是下面要说的。
Proposition 1:
设是一个凸而闭的集合,那么
(1) 投影存在且唯一。
(2) 对任意的当且仅当
,有
。
(3) 投影算子连续,并且有
,有
。
我们证明一下这个结论。第一个看起来好像很难,我们先看第二个。假如说我们有,那么注意到投影到的点满足的条件是与原始点的距离最小,所以一个常见的思路就是计算距离,并通过加减项的方式“拆出”我们想要的东西。具体来说,就是对于任意的
,有
然后只需要带入我们的结论即可(因为欧氏空间中,)。
另一方面,假如说我们有,那么这个时候对于任意的
,都会有
。现在我们假设我们有
,那么我们的思路就是沿着
的方向稍微走那么一点,来看看是否有反例。具体为什么这么做我们后面给大家解释。
设,那么这个时候,我们有
,设
,
,那么我们有
。那么这个时候不难得到
这里要注意的是,根据条件我们有,换句话说,一定会存在一个数
,使得
,这就矛盾了,因为一方面我们移动的距离很短,所以可以保证我们的点还在这个集合内,而另一方面,我们有要求过距离最小,但是我现在找到了一个新的点
,它的距离可以做到更小,这是不可能的。到此我们就算证明了这个结论。
这一张图说明了这个性质想告诉我们什么,也点出了证明思路。
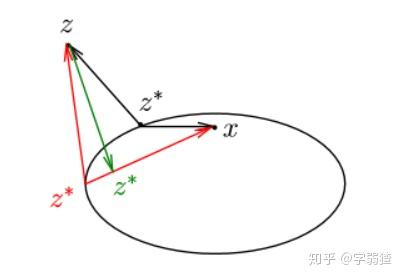
具体说就是,实际情况下,投影到两个我们关心的目标点的夹角应该是直角/钝角,如果是锐角的话,那么我们在
这一条线上一定可以找到一个点,使得
的距离变小,就不再符合投影的定义了。这也就是一个非常简单的“垂线段最短”的道理。
再来说说第三个结论,第三个结论其实就是利用一下我们的不等式。设,那么我们会有
简单的组合一下就会有$\\left \\le 0$,这样的话其实不难得到的是
两边约分即可得到我们想要的结果,而这个结果其实就隐含了算子的连续性。
关于第一个性质的证明,其实严格来说算是拓扑学的内容,简单来说,在一个有限闭集上取定义域的连续实值函数是可以取到极大极小值的。具体的细节我们这里不详谈,但是为了方便理解,我们放一个链接
学弱猹:拓扑学Ⅱ|笔记整理(4)——紧致性,列紧性在这里的Proposition 1有简单点一个类似的性质,虽然不完全一样,但理解够了。
有了这个性质我们说明下面的一个等价性质也就不困难了。
Proposition 2:
设的子空间(也就是说它是一个凸集),那么
,
当且仅当
。
简单说明一下,根据,分别代
并保证这两个新的点依然落在这个凸集内,就可以得到
,这也就说明了结论成立。
这里多说一句,就是虽然我们说的含义是要求对任意的
都要有
,但是我们这里的写法其实就足够说明这一点了,因为我们取的
的方向是任意的,只有它的长度会有要求不能太大,因为要保证
和
。而要说明向量与空间的垂直性,长度这个因素是不用考虑的。
下面我们给出带约束优化问题中,驻点的定义。
Definition 2: Stationary Point
若,那么称
是一个
的驻点。
这个定义实质上说明了带约束优化问题中我们对于极小值性质的考虑,而且可以看出来,在区域的内部的时候,可以推出,简单来说,你只需要让
的方向取的任意即可。下面这张图给了一个更直观的解释。
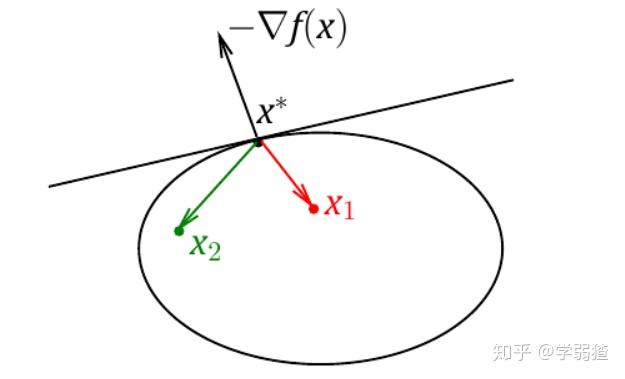
我们说过,只有目前你可以走的方向(这里的与
)与负梯度方向成一个锐角才有可能使得值下降,但是在边界上的时候,根据不等式条件你做不到这一点,那么这个时候就无法下降了,那么认为它是驻点自然也是合理的。
接下来我们给出驻点与投影之间的联系。
Proposition 3:
设。
我们证明一下这个结论。一方面,如果为驻点,那么会有
(因为
)。之后事实上做一个简单的变换就可以得到
,根据我们的Proposition 1的(2)即可得到结论。
另一方面,如果说我们有,那么这就说明了式子
成立,也就是说我们有
,这就足够说明
为驻点了。
所以其实对于这个结论,正反只是把话重复了一遍而已,没什么特别的。给出这一个性质作为铺垫,是因为我们后面的算法需要用到。
接下来我们给出局部极小值和驻点之间的关系。
Proposition 4:
设为
证明的思路和之前无约束优化的情形是非常类似的,设不是驻点,但却是局部极小值,那么我们考虑稍微移动一点
观察函数值是否会存在下降。根据Taylor展开会有

由于,这就相当于说我们有

这是因为,我们的是可以取的任意的小的,结合梯度的连续性,我们可以保证这个不等号依然是成立的。有了这个之后,我们就可以得到
,这就矛盾了。
接下来我们给出全局极小值与驻点之间的关系。
Proposition 5:
设
我们证明一下这个结论。一方面如果是全局极小值,那么肯定是局部极小值,那么推出驻点就用之前的写法就好。另一方面,如果说是驻点,我们的思考就是利用凸函数的性质来帮助我们思考。
事实上,根据凸函数的性质我们可以得到
通过简单的变换可以得到
令,根据我们的方向导数的公式(见第一节),我们有
,令
,那么结合驻点的性质
我们就可以得到
,这就足够说明结论了。
当然了,在带约束优化中我们也会碰到一阶信息失效的情况(也就是鞍点)。这个时候我们就需要利用到二阶信息,也就是下面这个性质。
Proposition 6:
若。那么我们有
。
这个性质的证明只依赖一步Taylor展开。还是一样,我们只需要利用局部极小值的性质,利用极小值点往任何一个方向走一点点,对应的函数值都比当前的值来的大这样的性质就好,也就是说
然后结合条件,结合就可以得到我们的结论。
推了这么多性质容易审美疲劳,我们来看两个例子,一个是正象限集(Positive Orthant),也就是,相当于要求变量的每一维都是非负。一个是边界集 (Bound Constraints),也就是
,其中
,也即是
的第
个元素。
首先我们来看的情况,我们希望观察的是驻点的一个等价形式。就像我们一直说驻点是优化的关键一样。
一方面,我们设,那么这个时候可以推出来
也就是说驻点需要满足的条件就是偏导非负。
另一方面,设对于某一个,
,并且有
,而对于其它的
,有
,那么我们会有
,也就是说对于每一个分量,我们都会有
,这就可以写出一个结果是
,那么因为
,结合偏导数非负,就可以得到
,换句话说,我们的第二个条件就是说,如果当前的维度变量是严格正的,那么就要求当前维度的偏导为0。
总结一下,就是
Proposition 7:
设上凸,且
为
,有
,当
,有
。
所以带约束优化的情况和无约束情况,至少在这个约束条件下,还是略有不同的。
接下来我们来看看的情况。事实上证明是类似的,和我们上面一样的写法可以得到
Proposition 8:
设为驻点,那么如果
,则偏导为0,若
,则偏导非负,若
,则偏导非正。
这两个限制条件的讨论,其实某种程度上告诉我们说,在边界上和内部对应的性态会不一样。基于这个原因,我们额外给出了下面的定义,它也会伴随着我们对于带约束优化问题的讨论。
Definition 3: Active/Inactive Sets
定义为
这个点对应的激活指标集,定义
为非激活指标集。
这里的激活的含义就是我们的边界是否起到了作用。我们可以看到讨论激活与非激活,是根据指标集来的,所以也对应的会有一些其它的定义产生。
Definition 4: Projection of Set
定义为指标集的投影。
直观来看,就是如果我们只保留了我们所需要的维度的信息,其它的都设置为0。
对于,我们要研究极小值的情况就会有些不同。这里的原因自然是在于边界的,不过我们只需要稍微修改一下我们的海塞矩阵即可,具体来说就是
Definition 5: Reduced Hessian
定义限制海塞矩阵满足
。
有了这个就比较好介绍下面的性质了
Proposition 9:
设边界下的局部极小值,若
半正定。
我们简单证明一下这个结论。事实上,有了投影的定义之后,就可以把每一个自变量写成下面这个形式
所以按照证明半正定的思路,我们事实上就是要说明,按照上面的拆解,事实上只会有两个部分留下来,即
和
(想想为什么?),而剩下的两个部分,一个根据无约束优化的情况可以知道它非负,另外一个通过我们对于限制海塞矩阵的定义可以得到为非负(因为对应的子矩阵是单位阵)。所以和非负,那么自然就说明它半正定了。
关于边界和非边界的最优性条件,我们还有一些额外的定义。
Definition 6: Non-degeneraity / Strict Complementarity
设,并且
,有
,那么称其为非退化的驻点。也被称为互补松弛性,因为我们有
。
为什么这个性质比较重要呢?从反面思考一下,如果一个点它对应在受约束的地方也没有一个比较好的下降,那么约束存在的意义是什么?事实上下面的性质可以帮助我们说明,如果我们具有非退化性(互补松弛性),那么我们会有一些与极值有关的额外条件。
Proposition 10:
设非空,那么存在
使得
,都有
。
简单说明一下这个结论。第一个等式自然不必多说,因为对于非激活的指标,我们有。而对于激活的点,事实上我们因为具有非激活的性质,它们的边界上的值非零,换句话说,我们可以找到一个
,使得
总结来说就是。因此我们自然可以得到
这是因为上面的没有下标的范数指的是2-范数,而。这是数值分析的内容,感兴趣的同学可以自己去证明一下。
这个性质其实就是为下面的这个定理服务的。
Proposition 11:
设为凸集,
尽管基本的思路还是一样,设,然后说明无论
会怎么取,稍微移动一点之后都会使得函数值不下降,也就是观察
的函数性质。但这里的证明和无约束优化的情况略有差别,原因就是在于在边界上,极小值的梯度不一定再是0。
为了解决这个问题,我们先求解,因为这就是
的一个基本情况。注意到
所以这就化归为两种情况,第一种就是,那么这种情况直接考虑利用上面的性质,可以得到
,换句话说无论往什么方向走,函数值都会上升,所以结论是成立的。
第二种就是,那么这个时候可以得到
,并且
这个地方注意到,相当于对于非激活的部分保留了原始的数据,而事实上,对于激活的部分,我们给它的海塞矩阵添加什么内容都没关系,因为它们的对应的维度都是0。所以事实上我们可以得到
这是因为既然添加什么都可以,那不如就添加一个单位矩阵了。而横正也是因为限制海塞矩阵的正定性。换句话说,在原点它的梯度为0,但是二阶导数恒正。这就是无约束优化的情况下极小值的等价性质,因此结论就成立了。
梯度投影法的基本思路和之前的最速下降法非常类似,也是一个相对来说很古老的用于解决带约束优化问题的方法。在此之前我们先介绍几个与投影有关的性质。
Proposition 12:
设,
,设
,那么有
,
。
事实上,这里的两个不等式,如果第一个证明出来了,第二个直接设就可以得到了。这里注意到,根据我们的条件和Proposition 1,可以得到
然后带入即可。
这些证明出来的不等式的一个最直接的推论就是
这句话的意思就是,我们选择的方向与负梯度方向呈锐角。注意我们的这个性质中,我们的前进方向受到投影的影响,不一定是严格的负梯度方向。但是有了一个锐角的结论,其实也算够用了。
接下来,我们祭出两个最常见的梯度投影法的形式,并给出它们对应的Armijo步长选取条件。


这两种形式分别对应为可行方向(feasible direction)形式和弧(arc)形式,它们俩对应的Armijo条件也略有不同。
Definition 7: Feasible Direction Armijo Condition
设,且
,那么如果
为使得
取值为最小的满足
的
,则称其满足可行方向情况下的Armijo条件。
这句话直接理解不是特别容易,直观来说和最开始介绍的线搜索方法的步长选取条件相同,也就是说我们的选取策略就是刚开始先找一个基准,然后每一步都缩小一个常数
,当满足那个不等式之后就停止迭代了。
对于arc形式的,要求也是差不多的
Definition 8: Arc Armijo Condition
设,那么如果
成立,那么称
哦,这两个翻译实在是太烫嘴了……
提到步长选取条件必然离不开步长的存在性。对于feasible direction form,这个不困难,因为我们是先投影,再下降的,所以下降方向的性质比较明确。但是对于arc form情况不太一样,因为arc form是先下降,再投影,那么你最后一步究竟把点投到哪里去了,就不好直观的看出来。因此我们需要一些其它的工具。
Proposition 13:
设为一个
的函数,
为Lipschitz连续的,且常数为
。如果
,那么我们有


我们证明一下这个结论。事实上,我们可以看出,所以通过Taylor展开就可以得到
这就证明了第一个式子。第二个式子也不难得到为
这就证明了第二个式子。
有了这个性质之后,我们就会有下面这个结论成立。
Proposition 14:
设,Armijo条件都可以成立,换句话说,步长收缩存在一个下界
。
要证明它,自然需要依赖上面的这个性质。注意到我们关注的是arc form,所以事实上有
我们的目的是要说明条件成立,所以一定要构造出一个相关的不等式来。事实上我们可以分开来看,注意到
所以通过一层绝对值不等式,我们可以得到
仔细观察这个式子与Armijo条件的差异,事实上只是差距在系数上。换句话说,我们只需要让
就可以了,简单化简一下不等式,就可以得到我们的结论。
通过这个结论,也就不难得到我们的最终步长的下界就是。换句话说,我们的步长不断的缩小的情况下,不会产生一直找不到步长的情况,这也就是步长的存在性了。
当然了,相信大家也会很关注它们的收敛性。我们列在这里但不会证明。
Theorem 1:
设
标准化的梯度投影法(Scaled Gradient Projection Method)是一种针对不同的投影量度而做的对应的修改。简单来说,我们一开始的投影的定义为
但是很多时候我们也会定义它为
其中,所以你也能看出来,
,我们都要求
。
它的具体的算法流程如下


这个方法也具有一定的收敛性,具体如下。同样的,我们也会略过证明。
Theorem 2:
设存在使得
,并设算法使用了feasible direction或arc形式的Armijo条件,那么算法也使得迭代点收敛到驻点。
对于为什么我们要做投影量度的变换,很多时候就是为了投影的计算方便,但是我们不会在这里提更多的细节。
好的,关于梯度投影法我们就说那么多。大家可以看出,对于这个方法我们没有太多的着力,也是因为它实在是有点古老了。但是这个方法的流程也可以一定程度上帮助大家理解带约束优化的执行过程。
本节我们主要是在构建一个理解带约束优化问题的框架,同时我们花很少的篇幅给大家介绍了梯度投影法。当然了,它都不算是带约束优化问题的主流,之后介绍的KKT条件和一些运筹的方法会带领大家更深刻的看待这一类问题。
——————————————————————————————————————

本专栏为我的个人专栏,也是我学习笔记的主要生产地。任何笔记都具有著作权,不可随意转载和剽窃。
个人微信公众号:cha-diary,你可以通过它来获得最新文章更新的通知。
《一个大学生的日常笔记》专栏目录:笔记专栏|目录
《GetDataWet》专栏目录:GetDataWet|目录
想要更多方面的知识分享吗?可以关注专栏:一个大学生的日常笔记。你既可以在那里找到通俗易懂的数学,也可以找到一些杂谈和闲聊。也可以关注专栏:GetDataWet,看看在大数据的世界中,一个人的心路历程。我鼓励和我相似的同志们投稿于此,增加专栏的多元性,让更多相似的求知者受益~


