

注:本篇博客大部分内容并非原创,而是本人将之前收藏的资料整理,并加以自己的愚解整合成到一起,方便回顾复习,所有参考资料均已注明出处,并已点赞加收藏~
前言:我们在复现网络的时候,不管是pytorch还是tensorflow,亦或是其他深度学习框架,都会使用到一个东西,那就是优化器,那么优化器到底是什么,有什么作用,优化器的种类有哪些?这一篇来进行探讨下~
优化器即优化算法是用来求取模型的最优解的,我们上一篇讲过,通过比较神经网络自己预测的输出与真实标签的差距,也就是Loss函数。关于loss的讲解可以参考链接:
pengtougu:从零开始学CV之二损失函数篇(上)为了找到最小的loss(也就是在神经网络训练的反向传播中,求得局部的最优解),通常采用的是梯度下降(Gradient Descent)的方法,而梯度下降,便是优化算法中的一种。
目前常见的优化器可以分为三大类:
2.1 梯度下降法(Gradient Descent)
- 2.1.1 标准梯度下降法(GD)
- 2.1.2 批量梯度下降法(BGD)
- 2.1.3 随机梯度下降法(SGD)
2.2 动量优化法
- 2.2.1 标准动量优化方法Momentum
- 2.2.2 牛顿加速梯度方法NAG
2.3 自适应学习率优化算法
- 2.3.1 AdaGrad算法
- 2.3.2 RMSProp算法
- 2.3.3 AdaDelta算法
- 2.3.4 Adam算法
梯度下降法是最基本的一类优化器,目前主要分为三种梯度下降法:
- 标准梯度下降法(GD, Gradient Descent)
- 随机梯度下降法(SGD, Stochastic Gradient Descent)
- 批量梯度下降法(BGD, Batch Gradient Descent)
假设要学习训练的模型参数为 ,代价函数为
,则代价函数关于模型参数的偏导数即相关梯度为
,学习率为
,则使用梯度下降法更新参数为:
从表达式来看,模型参数的更新调整,与代价函数中关于模型参数的梯度有关,即沿着梯度的方向不断减小模型参数,从而最小化代价函数。基本策略可以理解为”在有限视距内寻找最快路径下山“,因此每走一步,参考当前位置最陡的方向(即梯度)进而迈出下一步。可以形象的表示为:
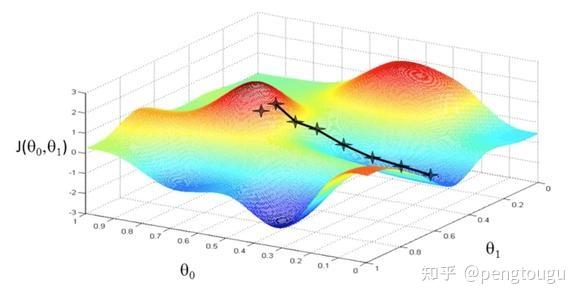
标准梯度下降法主要有两个缺点:
(1)训练速度慢:每走一步都要要计算调整下一步的方向,下山的速度变慢。在应用于大型数据集中,每输入一个样本都要更新一次参数,且每次迭代都要遍历所有的样本。会使得训练过程极其缓慢,需要花费很长时间才能得到收敛解。
(2)容易陷入局部最优解:由于是在有限视距内寻找下山的反向。当陷入平坦的洼地,会误以为到达了山地的最低点,从而不会继续往下走。所谓的局部最优解就是鞍点。落入鞍点,梯度为0,使得模型参数不在继续更新。
假设批量训练样本总数为 ,每次输入和输出的样本分别为
,
,模型参数为
,代价函数为
,每输入一个样本
代价函数关于
的梯度为
,学习率为
,则使用批量梯度下降法更新参数表达式为:
从表达式来看,模型参数的调整更新与全部输入样本的代价函数的和(即批量/全局误差)有关。即每次权值调整发生在批量样本输入之后,而不是每输入一个样本就更新一次模型参数。这样就会大大加快训练速度。基本策略可以理解为“在下山之前掌握了附近的地势情况,选择总体平均梯度最小的方向下山”。
BGD的优点:
对于凸误差面,批梯度下降可以保证收敛到全局最小值,对于非凸面,可以保证收敛到局部最小值。。

对比批量梯度下降法,假设从一批训练样本 中随机选取一个样本
,模型参数为
,代价函数为
,梯度为
,学习率为
,则使用随机梯度下降法更新参数表达式为:
其中, , 表示随机选择的一个梯度方向,
表示t时刻的模型参数。这里虽然引入了随机性和噪声,但期望仍然等于正确的梯度下降。基本策略可以理解为随机梯度下降像是一个盲人下山,不用每走一步计算一次梯度,但是他总能下到山底,只不过过程会显得扭扭曲曲。
随机梯度下降法优缺点:
(1)优点:虽然SGD需要走很多步的样子,但是对梯度的要求很低(计算梯度快)。而对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD都能很好地收敛。应用大型数据集时,训练速度很快。比如每次从百万数据样本中,取几百个数据点,算一个SGD梯度,更新一下模型参数。相比于标准梯度下降法的遍历全部样本,每输入一个样本更新一次参数,要快得多。
(2)缺点:SGD在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确。此外,SGD也没能单独克服局部最优解的问题。

动量优化方法是在梯度下降法的基础上进行的改变,具有加速梯度下降的作用。一般的动量优化法有:
- 2.2.1 标准动量优化方法Momentum
- 2.2.2 牛顿加速梯度方法NAG(Nesterov accelerated gradient)
2.2.1 Momentum
上面提到了SGD的一个缺点,就是在每个更新参数的时候,不一定是朝着梯度下降的方向,比如下面左边的图,我们更希望在水平方向上下降的快一点,而在垂直方向上的变化量小一点。添加动量的SGD就是在相关方向上计入 ,来加速SGD并且抑制震荡。


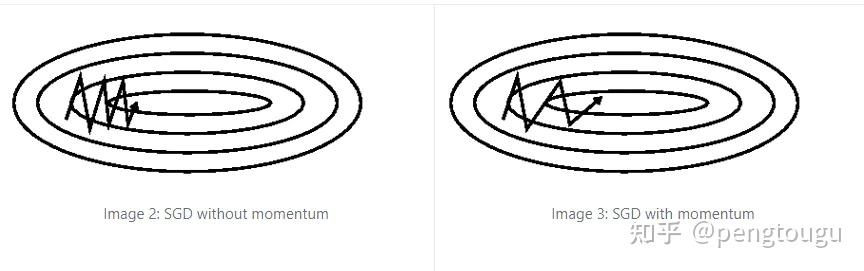
主要思想是引入一个积攒历史梯度信息动量来加速SGD,通常取 = 0.9,Momentum的作用如下图
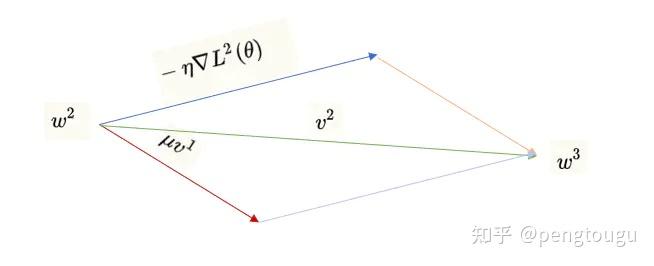
蓝色的箭头是不加动量时参数要指向的方向, 红色箭头是上一次的梯度下降指向的方向,如果是区域最小值在水平方向的右边,那么绿色箭头会比蓝色箭头更快到达区域最小值。
理解策略为:由于当前权值的改变会受到上一次权值改变的影响,类似于小球向下滚动的时候带上了惯性,这样可以加快小球向下滚动的速度。
优点
- 可以抑制震荡,加速收敛
缺点
- 需要调整学习率
2.2.2 NAG
Nesterov Accelerated Gradient 在momentum上做了一些改变, 计算了下一次参数的loss,具体的,通过公式进行分析:

其中, 表示
时刻积攒的加速度(形象看成惯性),
表示动量系数,一般取值为0.9,
表示
时刻的模型参数,
表示代价函数关于
的梯度,Nesterov动量梯度的计算在模型参数施加当前速度之后,往标准动量中添加了一个校正因子(加入了上一时刻积攒的加速度和动量系数的乘积),这样标准动量就包含了就对梯度的二次求导。
在原始形式中,Nesterov Accelerated Gradient(NAG)算法相对于Momentum的改进在于,以“向前看”看到的梯度而不是当前位置梯度去更新。经过变换之后的等效形式中,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。通过这个二阶导的近似能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。
上面的优化方法都用的是固定的学习率,缺点就是需要自己调参数找最适合的学习率,所以我们要想办法,让学习率在优化过程中一起优化了。自适应学习率优化算法针对于机器学习模型的学习率,采取一些策略来更新学习率,从而提高训练速度。
目前的自适应学习率优化算法主要有:
- AdaGrad算法,
- RMSProp算法,
- AdaDelta算法,
- Adam算法
AdaGrad算法优化策略可以表示为:
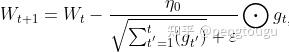
表示第
次迭代,初始的学习率取值一般为0.01,
是一个取值很小的数(一般为
)为了避免分母为0。
表示
时刻即第
次迭代模型的参数,代价函数
关于
的梯度。
一般来说AdaGrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢(学习率越来越小,导致 ,
的也越来越小,求导后的梯度更小)。
AdaGrad 的主要优势在于不需要人为的调节学习率,它可以自动调节;缺点在于,随着迭代次数增多,学习率会越来越小,最终会趋近于0。
RMSProp算法修改了AdaGrad的梯度积累为指数加权的移动平均,使得其在非凸设定下效果更好。RMSProp算法的一般可以表示为:
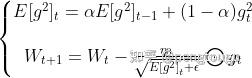
其中, 表示
时刻即第
次迭代模型的参数,
表示
次迭代代价函数关于
的梯度大小,
表示前
次的梯度平方的均值。
表示动量系数(通常设置为0.9),
表示全局初始学习率。
是一个取值很小的数(一般为1e-8)为了避免分母为0。
RMSProp借鉴了Adagrad的思想,观察表达式,分母为 。由于取了个加权平均,避免了学习率越来越低的的问题,而且能自适应地调节学习率(说白了就是学习率不在单调减小)。RMSProp算法在经验上已经被证明是一种有效且实用的深度神经网络优化算法。目前它是深度学习从业者经常采用的优化方法之一。
AdaGrad算法和RMSProp算法都需要指定全局学习率,AdaDelta算法结合两种算法每次参数的更新步长即:
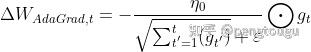
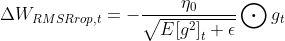
AdaDelta算法策略可以表示为:

其中 为第t次迭代的模型参数,
为代价函数关于
的梯度。
表示前 次的梯度平方的均值。
表示前t?1次模型参数每次的更新步长累加求根。在模型训练的初期和中期,AdaDelta表现很好,加速效果不错,训练速度快。在模型训练的后期,模型会反复地在局部最小值附近抖动。
首先,Adam中动量直接并入了梯度一阶矩(指数加权)的估计。其次,相比于缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。
Adam算法策略可以表 示为:

其中, 和
分别为一阶动量项和二阶动量项。
为动力值大小通常分别取0.9和0.999,
,
分别为各自的修正值,
表示t时刻即第t次迭代模型的参数,
为代价函数关于
的梯度;?是一个取值很小的数(一般为1e-8)为了避免分母为0。
评价:Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。

深度学习笔记-14.各种优化器Optimizer的总结与比较_业余狙击手19 ▄︻┻┳═一 - AI-CSDN博客
上图描述了在一个曲面上,6种优化器的表现,从中可以大致看出:
- ① 下降速度:三个自适应学习优化器Adagrad、RMSProp与AdaDelta的下降速度明显比SGD要快,其中,Adagrad和RMSProp齐头并进,要比AdaDelta要快。两个动量优化器Momentum和NAG由于刚开始走了岔路,初期下降的慢;随着慢慢调整,下降速度越来越快,其中NAG到后期甚至超过了领先的Adagrad和RMSProp。
- ② 下降轨迹:SGD和三个自适应优化器轨迹大致相同。两个动量优化器初期走了“岔路”,后期也调整了过来。
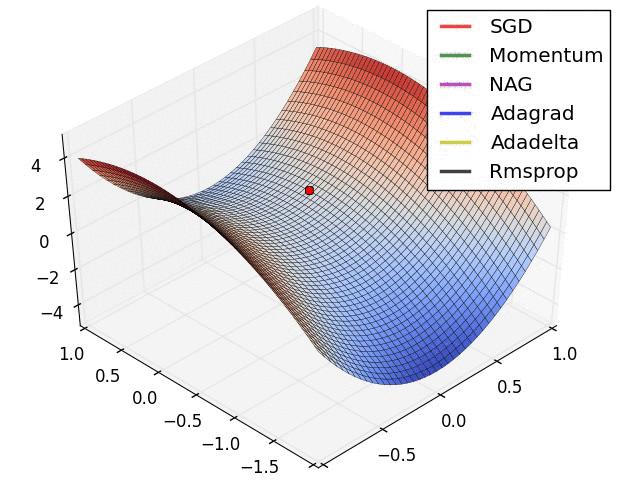
上图在一个存在鞍点的曲面,比较6中优化器的性能表现,从图中大致可以看出:
- ① 三个自适应学习率优化器没有进入鞍点,其中,AdaDelta下降速度最快,Adagrad和RMSprop则齐头并进。
- ② 两个动量优化器Momentum和NAG以及SGD都顺势进入了鞍点。但两个动量优化器在鞍点抖动了一会,就逃离了鞍点并迅速地下降,后来居上超过了Adagrad和RMSProp。
- ③ SGD进入了鞍点,却始终停留在了鞍点,没有再继续下降。
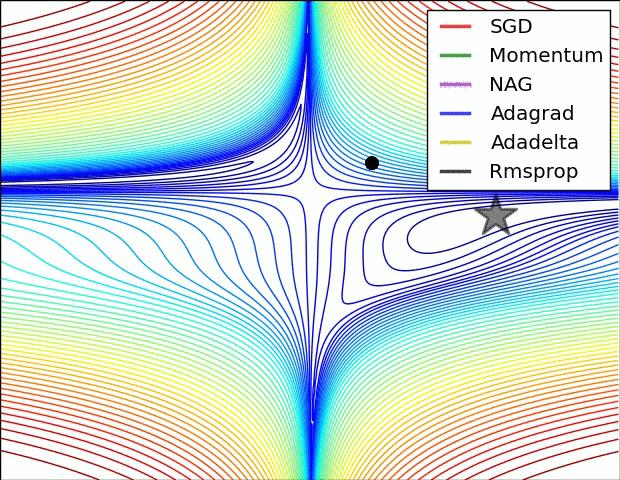
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
- 两个动量优化器Momentum和NAG的速度最快,其次是三个自适应学习率优化器AdaGrad、AdaDelta以及RMSProp,最慢的则是SGD。
② 在收敛轨迹方面
- 两个动量优化器虽然运行速度很快,但是初中期走了很长的”岔路”。
- 三个自适应优化器中,Adagrad初期走了岔路,但后来迅速地调整了过来,但相比其他两个走的路最长;AdaDelta和RMSprop的运行轨迹差不多,但在快接近目标的时候,RMSProp会发生很明显的抖动。
- SGD相比于其他优化器,走的路径是最短的,路子也比较正。
[1]深度学习--优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam) - 云+社区 - 腾讯云
[3]深度学习笔记-14.各种优化器Optimizer的总结与比较_业余狙击手19 ▄︻┻┳═一 - AI-CSDN博客


