

泻药。最近正好在做各种optimizer的survey,也来知乎看了一圈,发现还是一头雾水……各种公式满天飞,但是又前后不统一,让人摸不着头脑。所以就自己做了一份通俗易懂的理解,比较适合还不是很清晰底层原理的同学阅读。
大家在在做实验的时候经常会发现,训练前要确定一下代码:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)然后在训练的每个batch都要走一遍optimizer.step() 才能成功训练。什么是优化optimization?为什么要优化器optimizer?为什么大家很喜欢用SGD/Momentum/Adam呢?本文旨在弄清楚这三个核心问题。要搞懂这个问题,首先要搞清楚优化器到底是做什么的。而要知道优化器是做什么的,还得先弄清楚优化是做什么的……
很多大学的课,讲了一个学期,到头来还是对优化没能形成一个直观的认知。优化,通俗地讲,就是找到最优解。一个最简单的例子,二次函数找极值点,就是最简单的优化。这里二次函数就是一个模型,极值点就是目标,那自变量在 轴上移动的时候,就相当于在寻找(求解)最优解。
但优化的精髓在于,你拿到的问题,基本上不可能是二次函数。如果是二次函数,求最优解直接 不就完事了。实际情况下,你拿到都是些怪函数。举个最简单的例子,现在让你用MLP识别手写数字,输入图片的信号和你模型输出的信号的交叉熵损失函数就是你要优化的函数。这个函数够抽象吧,怎么去优化这个函数呢?换句话说,怎么找到这个函数的最大值呢?你根本没法用
这种closed-form形式来表示这个函数,这个函数说白了,就是一堆采样点。
在上面这个例子里,你有一堆模型参数 (就是weights)在MLP里,还有一个目标函数
(就是交叉熵损失函数)。你的任务,就是去改这个
,直到
取得最小值。也就是优化
。
好了,现在有了结论:什么是优化?优化就是最优化,找到一个函数的最优解(最大或最小)。什么函数的最优解?目标函数的最优解。为什么要找目标函数的最优解呢?因为它代表了模型的输出分布和数据的分布的不同程度。不同程度越小,模型输出和数据的分布越接近,也就是模型的预测越准。
刨根问底的你可能有问题,为什么交叉熵损失函数能衡量两组数据的分布呢?这就涉及到如何设计损失函数了,不得不看看这篇文章:
香农的信息论究竟牛在哪里?知道了优化是什么,就可以开始思考什么是优化器了。如果说优化是优化的过程,那么优化器就是优化的方式。优化过程就是找到最小值的过程,那么优化器就是如何找到最小值,说白了就是一个数学方法,只是在计算机领域,对数学方法的实现一般叫做算子operator,所以优化的过程其实就叫了optimizer。
也就是说,优化器就是一个方法,给定损失函数、输入分布、输出分布后,就可以开始在输入输出的对应中优化这个损失函数。那么具体有哪些方法呢?没错,梯度下降GD,随机梯度下降SDG,还有Adam这时候就出来了。
现在再看下面这段代码,相信你已经有很深入的理解了,不管我们optimizer用的是GD/SGD/Adam,下面的代码都不会变的,因为都不过是一种优化方法罢了。
for data , target in enumerate(train_loader):
optimizer.zero_grad () # 清空每个神经元的梯度grad
output = network(data) # 神经网络用输入算一遍结果 也就是forward pass
loss = F.cross_entropy(output , target) # 损失函数衡量两个分布的相似度
loss.backward () # 根据损失函数反向传播 更新每个神经元的梯度grad
optimizer.step () # 根据每个神经元的梯度grad和优化器的规则 更新每个神经元的weight每一个minibatch送到模型里面后,模型都会先产出一份输出,这份输出通过损失函数和训练集里面的数据做比较,然后反向传播回模型里面得到每个神经元的梯度,然后再通过这个梯度和优化器定义的规则对神经元的参数进行更新。
灵魂问题来了——很明显,这是个数学问题。先给个直观的理解:
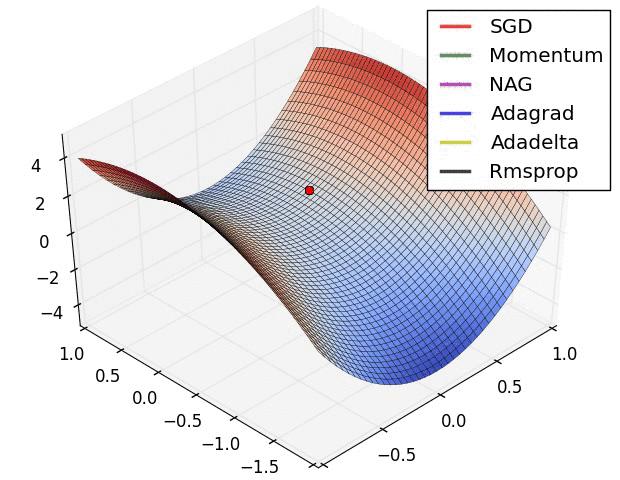
你看到的这个曲面就是在输入输出分布下的损失函数,这些小点就是不同的优化器是如何寻找最优解的。因为寻找是需要时间的,所以就变成了动图。现在让我们一个一个看过来。
知道你们都懒得划上去? ˙?˙ )? 我重新归纳一下优化到底要做啥。给你一堆模型参数 ,还有一个损失函数
,目标是找到
的最小值。
注意GD(梯度下降)是一个优化器的“大类”,包括最基础的Vanilla SGD,后面提出的Momentum SGD,Adagrad,RMSprop,Adam等,总体思想就是往梯度的反方向走!我们得先算当前时刻( 时刻)的一个梯度:
,然后根据这个梯度和之前所有的梯度算动量
和动量平方和
,然后就能更新模型参数了,
,称为GD更新通式。
一开始SGD没有动量,叫做Vanilla SGD,也就是没有之前时刻的梯度信息。所以 (
就是学习率),也就是当前时刻的
与之前时刻的梯度都无关。其他的就是
和
,这样代进通式就能获得
,看上去非常优雅。问题是没有动量的时候鞍点处震荡比较明显,学习率很难调,鲁棒性差。什么是震荡?看下面的图就一目了然了。
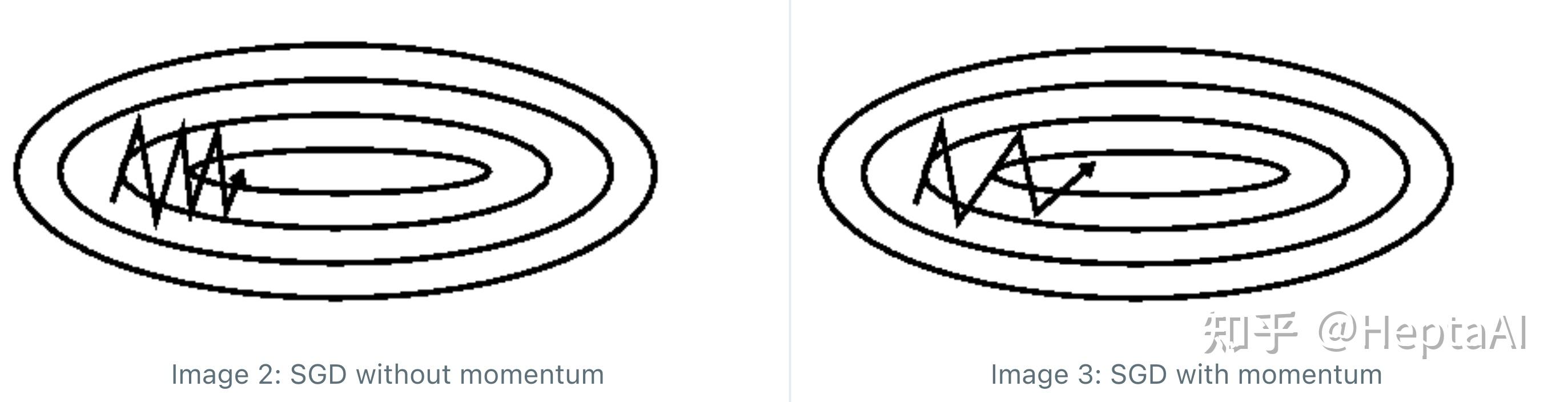
这个时候才引入了“动量”的意义,让通式真正起了作用。改变很简单,只要把Vanilla SGD的 改成
,也就是加上一个上一时刻的动量
,就能解决问题。其实这种SGD,在很多框架里就叫做Momentum。
别看名字不像,Ada梯度法也是一种GD方法,因此也满足GD通式!SGD方法总是以相同的学习率去更新所有的参数。但是深度学习中的大量参数更新的频率不同,例如word embedding中的低频词,更新频率低,往往需要步长更大,学习率更高;反之如果更新频率高,我们就需要学习率更小。大家想到了什么?不是给学习率除一个梯度就好了……于是就出现了 ,所以就看到了通式里面
这一项。
如果把这个新的学习率代回去,直接用公式表示 ,会发现
变成了一个对角矩阵,对角矩阵上的元素是从初始时刻到当前时刻梯度的平方和。
Adagrad有一个问题: 因为是平方和,所以是严格不为负的,而且学习率会逐渐收敛到 0,这样训练就直接结束了,不是我们想要的结果。RMSprop的设计初衷就是为了避免学习率的收敛。仔细观察Adagrad,用了从初始时刻到当前时刻的全部梯度信息,那么RMSprop要做的就是只用部分梯度信息去求
,公式是
,其实就是只用了上一时刻的
和这一时刻的梯度。这样,学习率的更新受之前学习率的影响就小了很多,从而避免了学习率收敛问题。具体地说,这种方法叫做指数移动平均法,也称“窗口法”。
大的来了。什么是Adam?就是RMSprop+momentem。Adam使用RMSprop的指数移动平均法计算 和
(比RMSprop牛在
用的也是一个窗口,RMSprop只有
用了窗口),仔细看看下面的
和
,是不是发现和RMSprop的公式如出一辙:
Adam还有一个细节,就是 这两个初值都是 0,这样训练初期
会过度偏向 0,这个可以通过增加一个偏置校正来解决,具体的就不展开了。
Juliuszh:Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪
骆梁宸:从 SGD 到 Adam —— 深度学习优化算法概览(一)
余昌黔:深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
https://ruder.io/optimizing-gradient-descent/index.html#momentum


