


神经网络的参数众多,我们需要选择合适的算法来进行参数的更新和学习,也就是优化器。优化器在神经网络模型训练的过程中有着十分重要的作用。
从SGD开始,神经网络模型优化器就一直在迭代和发展之中。如PyTorch就已经开源了包括SGD、Momentum、RMSprop、Adam、AdamW等等丰富的优化器。但是,由于深度学习模型本身的复杂性,深度学习模型框架自带的优化器本身可能并不能很好的适应我们的任务需求,因此我们有时候需要根据自己的任务去定义合适的优化器,让深度学习模型的优化能更加顺利。
?01?
动机

要写这篇关于《如何使用MindSpore优化器》博客的起因是由于在复现DeppMind的论文《High-Performance Large-Scale Image Recognition Without Normalization》(https://arxiv.org/abs/2102.06171),也就是NFNet。关于NFNet的介绍,大家可以参考博客
最强ResNet变体!归一化再见!DeepMind提出NFNet,代码已开源!(https://zhuanlan.zhihu.com/p/350766415)。
?02?
层归一化的缺陷
在计算机视觉领域,神经网络的训练过程中,虽然诸如BatchNorm(主要用在CNN中,以下称为BN)、LayerNorm(主要用在ViT中,以下称为LN)能够为训练带来很稳定的收敛,在一定程度上可以提高模型的指标,但是两者带来的弊端也是不容忽视的。对于BN层来说,模型最后的精度很容易受到BatchSize的影响,当BatchSize很小的时候,模型最后的指标会发生严重的下降。为了缓解这一现象,研究者们提出了很多替换BN层的归一化方法,目前在ViT中广泛使用的LN。尽管LN具有样本之间的独立性,模型的最后指标几乎不会受到BatchSize的影响,但是LN层的存在却会大大的降低模型的单步训练时长,也可以说:LN本身的一个硬件不友好的operation。
?03
自适应梯度裁剪
从作者的论文中可以看到,作者使用了一种名为自适应梯度裁剪的技术,相关的代码可以参见nfnets_pytorch(https://github.com/benjs/nfnets_pytorch/blob/master/nfnets/optim.py)。这里我将结合代码和数学公式对论文里面的自适应梯度裁剪技术进行说明。
通过理解公式我们可以简单理解为,当梯度的范数大于一定程度的权重范数时,梯度会进行缩放,反之梯度保持为原来的值,这就是其中自适应三个字的由来。
?04?
如何用MindSpore自定义优化器并且实现AGC_SGD
要用MindSpore优雅的实现AGC_SGD(主要是想尽量少用for循环,尽量接近MindSpore 的原生程序风格),我们首先要来了解一下MindSpore优化器的整体优化器的优化构建。以下的代码片段有一些跳跃,希望大家紧跟思路,抓住核心的代码片段就好。
mindspore.nn.optim.Momentum
MindSpore的优化器整体定义和其他框架类似,都是从一个Optimizer基类继承来的op。在PyTorch中SGD似乎是和Momentum写在一起的,因此这里拿Momentum为例。对于Momentum而言,
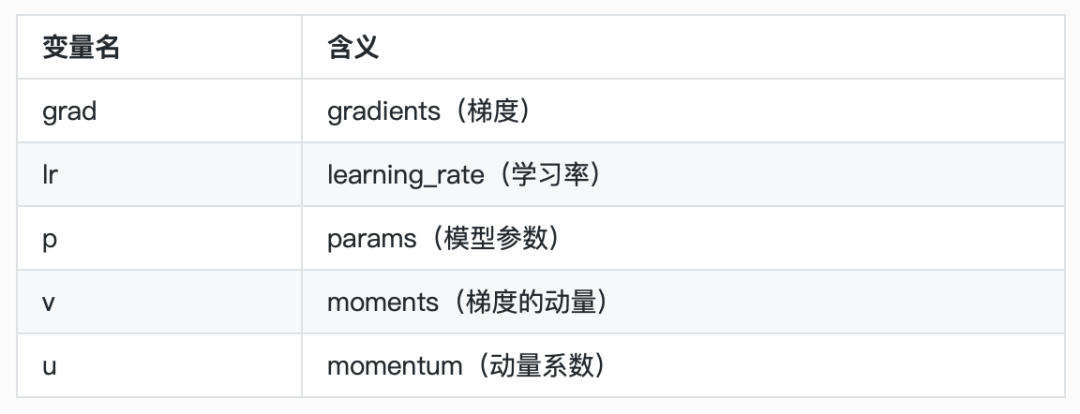
以下的Momentum优化器的更新准则(暂时忽略weightdecay)
首先是得到
$$当前梯度动量 = 过去动量 imes 动量系数 + (1-动量系数) imes当前的梯度$$
用公式表示也就是:
$$v{t} = v_{t-1} \ast u + (1-u) imes gradients$$
当use_nesterov=False的时候,就完成单步的更新,同时,相对应的动量也会得到更新。关于use_nesterov参数,感兴趣的读者可以查找牛顿动量(Nesterov)算法
If use_nesterov is?True:
$$p{t} = p{t-1} - (grad imes lr + v_{t} imes u imes lr) $$
If usenesterov is?False:
$$p{t} = p{t-1} - lr imes v{t}$$
可以看到,在更新的过程中,我们既可以等到为下一步准备的当前动量,也可以完成最后参数的更新,以此往复,不断更新参数。
在优化器的运行阶段,我们可以看到,大体上就是执行了
-
权重衰减
-
梯度缩放(估计是为了配合缩放器加的参数,假定scale=1.,我们传入优化器前就对混合精度完成缩放,可以看到我之前的如何使用MindSpore进行自定义训练)
-
梯度中心化(这个功能默认是False,op里面不会去执行,因此不用太过于在意)
-
完成单步更新(group_lr是指针对不同的参数使用不同的lr,感兴趣的可以尝试)
在Momentum中,我们可以看到一个if的逻辑判断,从大体上就可以了解到,估计就是判断是不是优化器中包含过往的动量信息,_ps_pull和_ps_push操作估计就是为了保存下过去的缓存信息。
另外,根据作者的意思,最后一层的全连接层的weight权重是不需要使用AGC为好,因此我们可以构建 self.group_clipping_tuple: List[Bool,]对其进行针对name的判断。在优化器中,为了针对不同的权重(weight、bias、gamma、beta),针对权重衰减的weight_decay也会根据参数的顺序转化成一个列表进行权重和weight_decay的一一映射关系。具体的代码可以参见Optimizer源码
(https://www.mindspore.cn/docs/api/zh-CN/r1.3/_modules/mindspore/nn/optim/optimizer.html#Optimizer)。
至此,我们就依赖于MindSpore本身自带的Momentum函数,完成了MindSpore实现AGC_SGD的功能,代码过段时间我会提交MindSpore官方的model仓库,感兴趣的小伙伴到时候可以自取。

MindSpore官方资料
GitHub :?https://github.com/mindspore-ai/mindspore
Gitee :?https : //gitee.com/mindspore/mindspore
官方QQ群 :?486831414?


